Buffer缓冲区的原理及应用
Buffer的原理及应用
缓冲区的概念
数据在缓冲区中排队,你先入先出的形式读写。先写入的数据先被读出来。所以看上去缓冲区像一个水管,数据流入缓冲区,然后再流出。

缓冲区内部是用于存储数据的数据结构。可能是数组、可能是链表、甚至可能是复杂的树结构,比如哈希表、树等等都有可能。
比如一个聊天服务,在处理用户发送的消息时,例如微信,一定不能马上处理这条消息。而是应该先缓冲。如果你马上处理这些消息,当并发量高的时候,总有你处理不过来的时候。而你对消息进行了缓冲有很多的好处,首先是避免了瓶颈的出现(运算性能的瓶颈。Io性能的瓶颈)。其次,有时候批量处理数据的成本更低。比如批量写入磁盘。批量发送网络请求。可以更好的利用底层的设施,比如批量写入磁盘数据就比单个一点点写入快很多很多,这些都是缓冲区的价值。
缓冲区操作
- flip() 翻转:读写切换
- clear() :清空缓冲区
- rewind() :重读或重写
flip操作
读取这样的缓冲区就需要进行缓冲区的翻转,也就是flip操作。
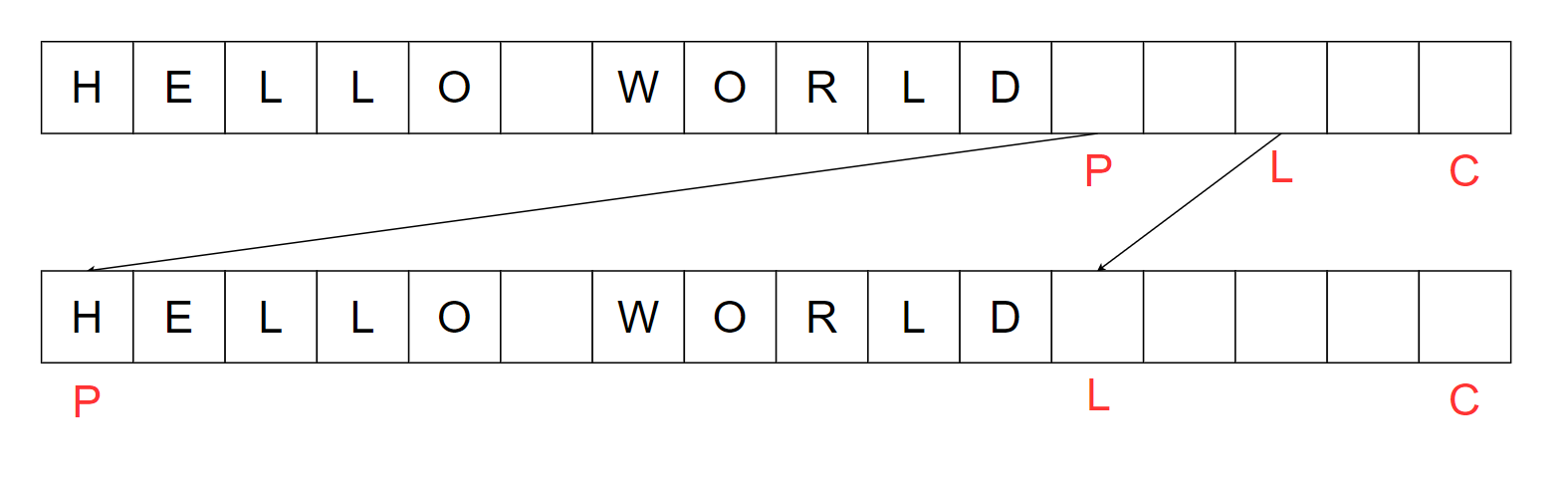
上图中的flip操作,将position设置为0,limit设置为position的位置。这样就从一个写入缓冲区,切换到了读取缓冲区。接下来,我们就通过指针P就可以读取缓冲区的内容,而limit左边的就是有数据的。
所以flip操作的作用是帮助缓冲区在读写之间切换。
通过这个例子,你会发现,limit才缓冲区的实际数据范围,Capacity是一个物理限制。
clear操作
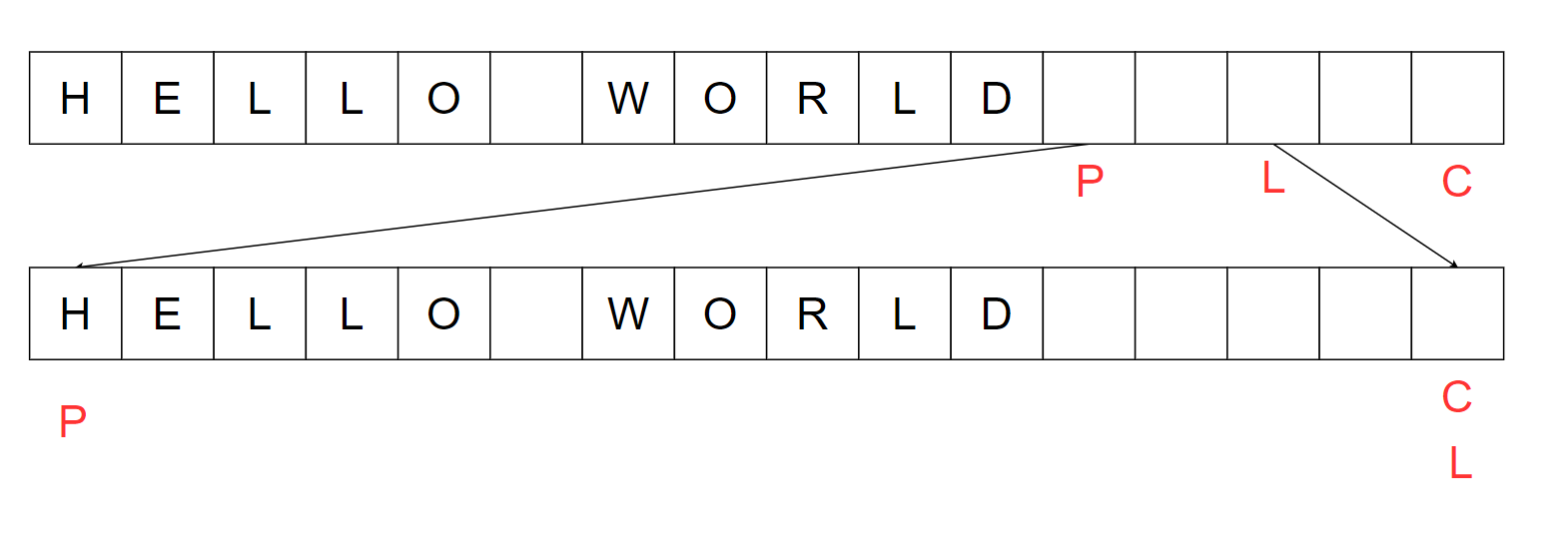
当缓冲区使用完可以进行清空。清空操作将缓冲区恢复到初始状态。也就是position=0,Limit=Capacity的状态。这个操作称之为clear操作,如下图所示。
rewind操作
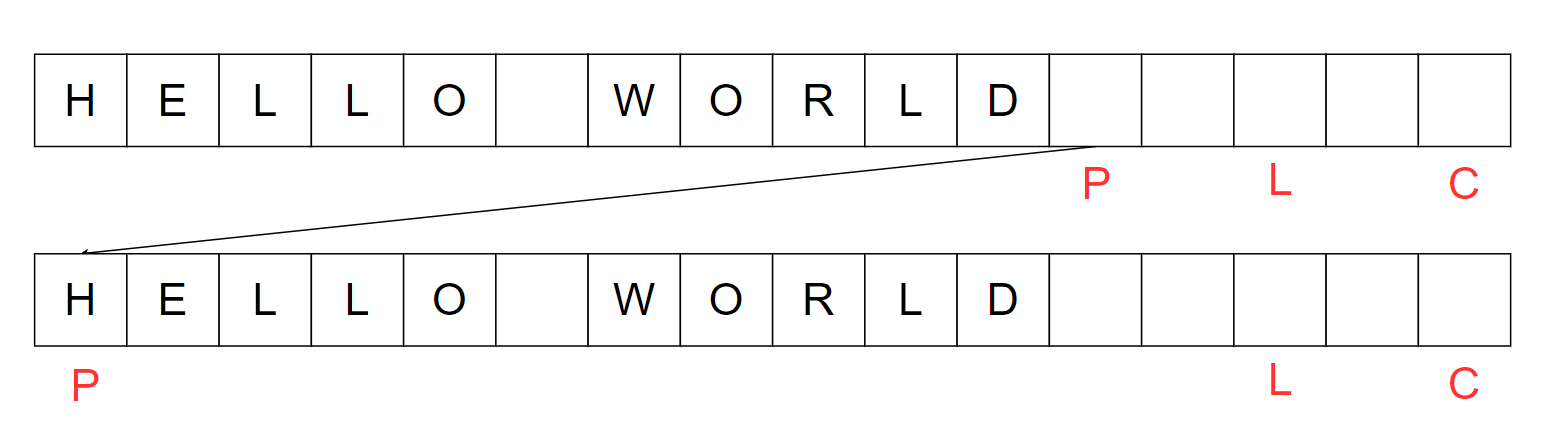
另外,有时候我们需要重新读取流中的数据。这个时候,就像倒带(rewind)一样,需要将position置0,其他不变。
[ ](https://book.weavinghorse.com/smile-java/docs/2-5 buffer/#实战举例)
本博客所有文章除特别声明外,均采用 CC BY-NC-SA 4.0 许可协议。转载请注明来源 Alfred的小站!
相关推荐

2021-08-16
jvm如何加载.class文件
jvm如何加载.class文件JVM是一个内存中的虚拟机 Class Loader:根据特定格式,加载class文件到内存 Execution Engine:解释器,对命令进行解析 Native Interface:融合不同语言的原生库为java所用 Runtime Data Area:JVM内存空间结构模型 由Class Loader加载.class文件到内存,Execution Engine进行解析运行,如果有native方法交给Native interface执行

2021-04-11
反射
反射Java反射机制是在运行状态中, 对于任何一个类,都能够知道这个类的所有属性和方法; 对于任何一个对象,都能够任意调用他的方法和属性; 这种动态获取信息和动态调用对象方法的功能就叫做反射机制。

2021-04-11
内存模型
内存模型 Runtime Data Aera Method Area:是Java虚拟机规范中的概念,在HotSpot的实现中: JDK7及以前,HotSpot用永久带来实现方法区,存在jvm内存中,与堆连续的地址空间,GC和老年代一起。 JDK8及以后,HotSpot把很多东西放到了堆或者本地内存,而方法区则成为了元空间的实现,同时元空间不再与堆连续,而且是存在于本地内存(Native memory)。 JVM内存模型 线程私有:程序计数器,虚拟机栈,本地方法栈 线程共享:MetaSpace、Java堆 程序计数器(Program Counter Register) 是一块较小的内存空间,可以看做是当前线程所执行的字节码行号的指示器; 字节码解释器工作时,通过改变计数器的值选取下一条执行的字节码指令;(一些基本功能都需要依赖计数器来完成 如 分支 循环 跳转 异常处理 线程恢复...
2021-04-11
常考题型
JVM三大性能调优参数 -Xms -Xmx...

2021-04-11
GC
GC 垃圾回收机制判断对象是否为垃圾的算法引用计数算法 通过判断对象的引用数量来决定对象是否可回收 每个对象实例都有一个引用计数器,被引用则+1,完成引用则-1 优点:执行效率高,程序执行受影响较小 缺点:无法监测出循环引用的情况,导致内存泄露 由于其缺点的存在,主流JVM基本不使用此方式。 可达性分析算法 通过判断对象的引用链是否可达来就决定对象是否可以被回收 对内存中的整个对象图进行遍历,从GC Root开始,回收器将所有访问到的对象标记为存活,完成遍历后不可达的对象会被作为垃圾对象而清除。 可以作为GC Root的对象 虚拟机栈中引用的对象(栈帧中的本地变量表) 方法区中的常量引用的对象 方法区中的类静态属性引用的对象 本地方法栈中JNI(Native方法)的引用对象 活跃线程的引用对象 垃圾回收算法标记-清除算法(Mark and...
2021-04-11
ClassLoader
ClassLoader类从编译到执行的过程 编译器将源文件转化为字节码文件 ClassLoader将字节码转化为JVM中的Class<T>对象 JVM利用Class<T>对象实例化为T对象 ClassLoaderClassLoader在java中有着非常重要的作用,它主要工作在class装载的加载阶段,其主要作用是从外部系统获得class二进制数据流,它是java的核心组件,所有的class都是由ClassLoader进行加载的,ClassLoader负责通过将class文件里的二进制数据流装进系统,然后交给java虚拟机进行连接、初始化等操作。 ClassLoader的种类 BootStrapClassLoader:C++...